-
AI FactoryAI FactoryAI Factory – already hereThe AI Factory is no longer a concept — it’s a reality.

-
NeoCloudNeoCloudAI Factory – already hereThe AI Factory is no longer a concept — it’s a reality.
-
SolutionsSolutions
-
CompanyCompany


The private alternative to Claude Code: Run a sovereign AI coding assistant on Nebul’s AI Factory
Every developer team we talk to has the same story. Someone tries Claude Code, comes back to standup won over, and within a week half the engineering team has adopted it. Then the pricing changes. Then the rate limits tighten. Then the model you optimised your workflow around gets quietly deprecated.
By the time you’ve built your engineering culture around a single vendor’s toolchain, you’re no longer a customer. You might be a captive.
Claude Code is genuinely impressive, it plans, executes, edits across files, runs tests, and iterates. But “impressive” and “the right long-term choice” are different questions. For a growing number of teams, the golden cage is starting to feel less golden.
Three things are driving that shift.
The lock-in problem nobody wants to talk about
Most conversations about AI coding tools focus on capability: benchmark scores, context windows, how well it handles multi-file refactors. These things matter. But they’re not what creates problems six months after adoption.
What creates problems is this: when you build your engineering workflow around a closed-source tool, you hand over control of three things you probably didn’t mean to give up.
- Pricing. Claude Code’s token costs have shifted multiple times. Input costs sit at $5.00/M tokens today, but that number is set by Anthropic, not by you, and it can change with a blog post. Teams that didn’t model for cost volatility have had uncomfortable conversations with finance.
- Model flexibility. Claude Code runs Anthropic models. That’s it. When a better model for your specific workload ships (from a different lab, with different strengths) you can’t use it without changing your entire toolchain.
- The agent itself. Claude Code is a closed-source agent. You can’t inspect it, fork it, extend it, or adapt it when it doesn’t behave the way you need. Open-source alternatives have caught up significantly on capability, and they give you something Claude Code structurally cannot: control over the harness, not just the model.
This is what vendor lock-in looks like in practice. And as it looks, it is not a dramatic failure, just a slow accumulation of decisions.
An additional reason legal keeps saying no: where your code goes
For most engineering teams, the lock-in argument is enough. But for teams in regulated industries (ie. fintech, healthtech, enterprise SaaS) there’s a second layer worth understanding.
With Claude Code, requests are sent to Anthropic’s API and processed on US-based cloud infrastructure. Their commercial terms specify that customer data isn’t used for model training, but this is a contractual commitment, not technical control.
For international teams, the CLOUD Act adds another dimension. This US federal law permits American authorities to compel disclosure of data held by US-based companies, regardless of where that data is physically stored. EU data residency doesn’t resolve this if the service provider remains a US entity.
For a fintech team handling transaction logic or a healthtech company with clinical decision systems, this isn’t hypothetical. It’s the reason your legal team says no and it’s a structural compliance gap that contractual commitments can’t close.
If your team is in this category, data sovereignty isn’t a secondary concern. It’s a hard requirement. The good news is the same setup that solves lock-in also solves this.
OpenCode and a different approach
The answer isn’t to block your engineers from using AI coding tools. The answer is to change who controls the stack.
OpenCode is the open-source coding agent built by the team behind SST, with 160K GitHub stars and 7.5 million monthly active developers. It supports the same core workflows as Claude Code: multi-file edits, shell command execution, test iteration, and MCP server integrations.
The architectural difference is fundamental. OpenCode provides the harness: planning, file editing, terminal execution, git integration, while you decide where the intelligence comes from. That means you can point OpenCode at any OpenAI-compatible API endpoint, swap models without changing your workflow, inspect and fork the agent itself, and avoid paying a premium for a closed stack you don’t control.
What "private" actually means when paired with Nebul
Nebul’s AI Factory provides private inference endpoints that are OpenAI-compatible, which means OpenCode can point to them directly with zero changes to your workflow. The models run on Nebul’s NeoCloud infrastructure, hosted in European data centres, under EU jurisdiction, with full GDPR compliance and ISO 27001 certification and no exposure to US Cloud Act jurisdiction.
Your code never leaves the endpoint you control. No third-party eyes on your proprietary logic. Full audit trails for every inference request if you need them.
On the model side: the gap between proprietary models like Claude Opus 4.7 and frontier open models such as GLM 5.1 or Kimi 2.6 has closed significantly. For most coding tasks, the difference is marginal and getting more marginal every quarter.
The architecture is simple:
| Your terminal or IDE
↓ OpenCode — open-source, runs locally, zero data retention ↓ Nebul Private Inference API — EU-hosted, GDPR-compliant, ISO 27001 ↓ Your chosen model — GLM, MiniMax, Kimi, and 50+ others |
Nothing in that stack touches US infrastructure. Nothing leaves your jurisdiction.
Setting it up
This takes about 15 minutes from scratch.
What you need before you start:
- An active Nebul account with API access (docs.nebul.io)
- OpenCode installed (instructions below)
- Your Nebul API key and inference endpoint URL from the Nebul AI Studio
Step 1: Install OpenCode
OpenCode runs in your terminal, as a desktop app, or as a VS Code extension. For most teams, the terminal version is the most flexible.
For macOS users (recommended): The easiest way to install and keep OpenCode updated on Mac is via Homebrew:
| brew install anomalyco/tap/opencode |
Via NPM: If you prefer using Node.js or are on a different operating system:
| npm install -g opencode-ai |
Or download the desktop app directly from opencode.ai — available for macOS, Windows, and Linux.
Step 2: Configure your Nebul private endpoint
OpenCode uses a config file to set up your model provider. Open or create ~/.config/opencode/opencode.json and add:
| {
“$schema”: “https://opencode.ai/config.json“, “model”: “nebul/zai-org/GLM-5.1-FP8”, “provider”: { “nebul”: { “npm”: “@ai-sdk/openai-compatible”, “name”: “Nebul Inference API”, “options”: { “baseURL”: “https://api.inference.nebul.io/v1“ }, “models”: { “zai-org/GLM-5.1-FP8”: { “name”: “GLM 5.1 FP8”, “limit”: { “context”: 128000, “output”: 16384 } } } } } } |
Run Opencode in your terminal
Run /connect, scroll to Other, and enter a provider ID nebul.
Paste your Nebul API key when prompted.
Model choice: Our recommended default is GLM-5.1 a frontier-class open-weight model from Z-AI that we run on Nebul daily. More on why below. Check https://docs.nebul.io/docs/inference-api/models/model-catalog for the full list and context window sizes.for the full list and context window sizes.
Step 3: Verify the connection
Run OpenCode in your terminal from any project directory:
opencode
Start with something simple to verify your private endpoint is live eg. “summarise what this repo does” or “find all the API endpoints defined here.” A coherent answer means the full stack is working.
Step 4: Set context window to match your model
In your config, set the context window to match your chosen model. GLM supports up to 128k tokens:
| {
“provider”: { … “maxTokens”: 128000 } } |
For large codebases, this matters. OpenCode will index your repo and include relevant context in each request, a larger window means it can hold more of your codebase in view at once.
Step 5 (optional): Add shared codebase indexing with QDrant
If you want multiple engineers to share semantic codebase indexing (so the AI understands your repo structure across team members) you can add a shared QDrant instance. Nebul’s NeoCloud supports hosted QDrant containers, keeping the index private and within your infrastructure.
This is the same setup we covered in our Roo Code / Kilo Code tutorial the configuration transfers directly.
What you gain, and what the trade-off is
Let’s look at the numbers. While the top-tier closed models sit high on SWE-bench, the gap in real-world agentic capability is smaller than marketing suggests.
OpenCode with GLM 5.1 handles the overwhelming majority of day-to-day coding tasks with the same precision as Claude-based setups. The minor difference in benchmark scores only shows up at the extreme edges, in other words, highly ambiguous tasks where specific reasoning depth is tested. For standard refactoring, testing, and feature implementation, the difference is marginal.
Does the model hold up?
The short answer: yes, for coding tasks specifically.
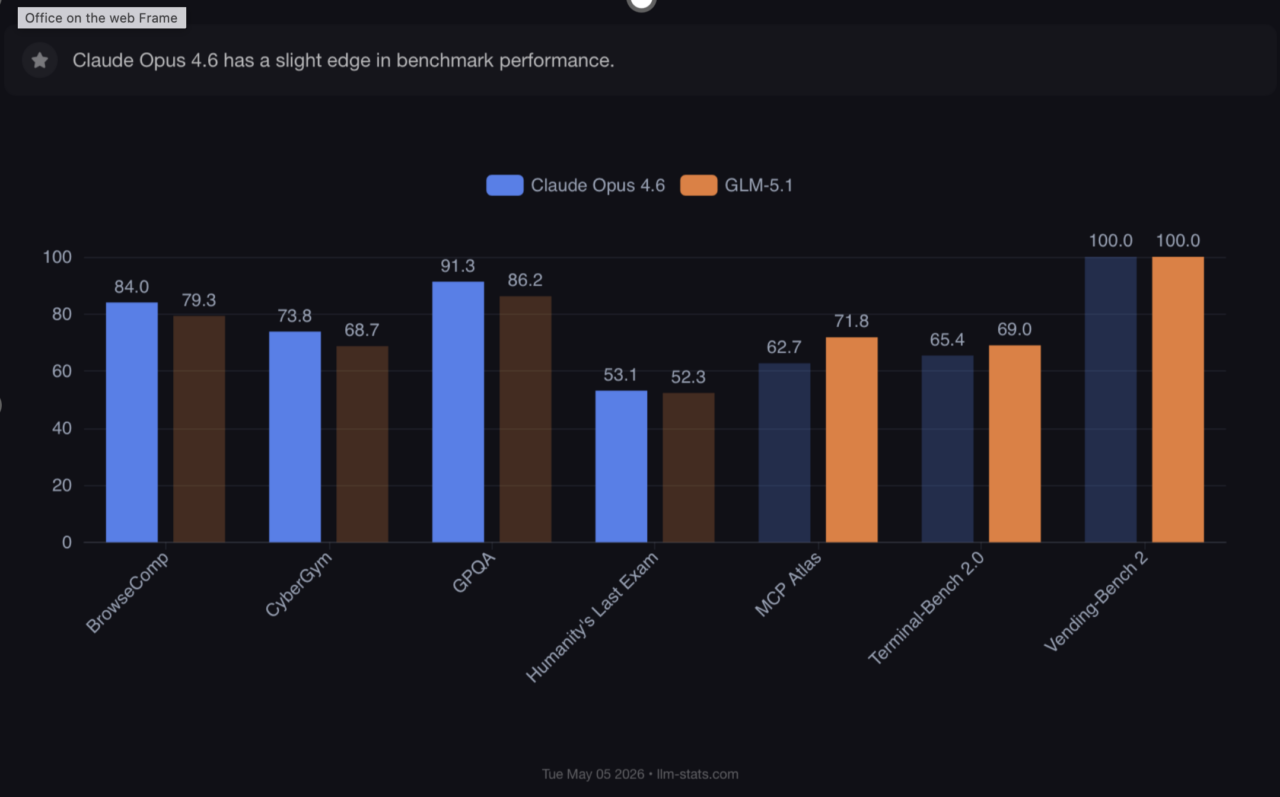
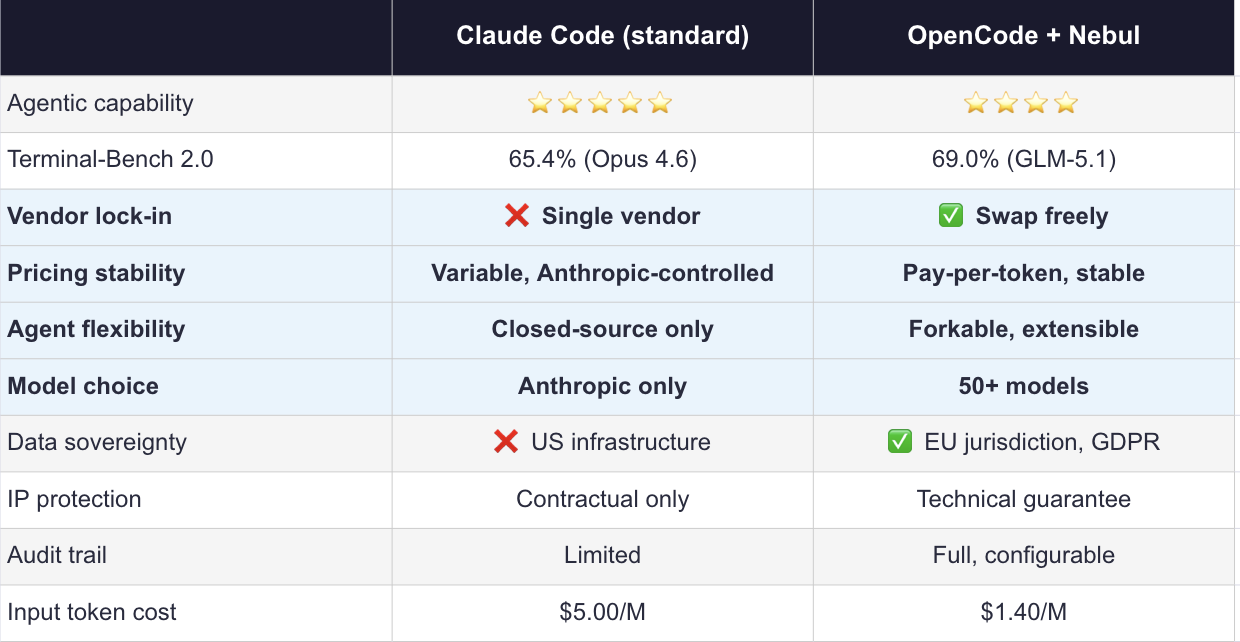
GLM-5.1 leads Claude Opus 4.6 on the benchmarks most relevant to this use case — Terminal-Bench 2.0 (69.0% vs 65.4%) and MCP Atlas (71.8% vs 62.7%), both designed to evaluate agentic and tool-use workflows. It’s also 3.6–5.7x cheaper per token. (Source: llm-stats.com)
Claude Opus 4.6 has a larger context window and stronger general reasoning on some benchmarks if that matters for your workload, it’s worth factoring in. But for the day-to-day coding loop, the numbers don’t support the assumption that closed-source is in a different tier.
Who this is for
This setup makes the most sense for:
- Engineering teams frustrated with pricing volatility who want predictable, stable costs they control
- Fintech and healthtech SaaS teams whose legal team has already blocked Copilot or Claude Code on IP grounds
- SaaS companies selling to enterprise clients who will ask “where does your AI infrastructure run?” during procurement
- Engineering teams in regulated industries who need provable data residency for compliance audits
- Any team that considers its codebase a competitive moat and doesn’t want it touching infrastructure they don’t control
If that sounds like your team, and increasingly, it sounds like most European SaaS teams, this is a setup worth taking seriously.
Try it
Nebul offers private inference endpoints with a free trial period. You can have the full setup — OpenCode pointed at a private Nebul endpoint, running on EU infrastructure — working in an afternoon.
Start with a private workspace →
Or if you want to walk through the setup with a Nebul solutions engineer: book a 30-minute call and we’ll do it together.
Related: Read blog Building a Secure AI Coding Assistant with Roo Code, Kilo Code on VSCode